Data Protection and Privacy - Europe and the U.S.
If you had a meeting and Apple CEO Tim Cook gave a speech and he was followed by Sir Tim Berners-Lee, and after the lunch break Facebook's Mark Zuckerberg and Google's Sundar Pichai were on the screen giving video messages, you would consider this to be a pretty high-powered meeting.
That was the lineup for some European data regulators at the 40th International Conference of Data Protection and Privacy Commissioners, held this year in the European Parliament in Brussels.
I saw part of it on a recent 60 Minutes. Tim Cook talked about the "crisis" of "weaponized" personal data. It's not that Apple doesn't collect data on its users, but companies like Facebook and Google rely much more on user data to sell advertising than hardware-based Apple.
The focus in that segment is on Europe where where stricter laws than in the U.S. are already in place. Of course, they affect American companies that operate in Europe, which is essentially all major companies.
Multi-billion dollar fines against Google for anti-competitive behavior re in the news. The European Union enacted the world's most ambitious internet privacy law, the General Data Protection Regulation (GDPR).
Tim Cook said he supports the law, but Jeff Chester, executive director of the Center for Digital Democracy, says that "Americans have no control today about the information that's collected about them every second of their lives." The only exception is some guaranteed privacy on the internet for children under 13, and some specific medical and financial information.
This is an issue that will be even more critical in the next few years. Since GDPR was passed, at least ten other countries and the state of California have adopted similar rules. And Facebook, Twitter, Google, and Amazon now say they could support a U.S. privacy law. Of course, they want input because they want to protect themselves.


Data and Goliath: The Hidden Battles to Collect Your Data and Control Your World
 Facebook has had a tough year in the press and with its public face (though its stock is holding up fine). There has been a lot of buzz about hacks and data being stolen and fake news and Senate hearings and general privacy concerns. All of these are legitimate concerns about Facebook and about other social media and e-commerce and financial site too.
Facebook has had a tough year in the press and with its public face (though its stock is holding up fine). There has been a lot of buzz about hacks and data being stolen and fake news and Senate hearings and general privacy concerns. All of these are legitimate concerns about Facebook and about other social media and e-commerce and financial site too.


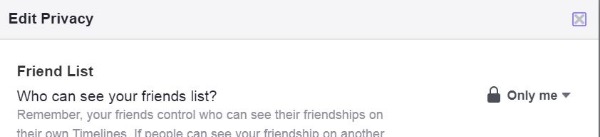 Run A “Privacy Checkup” by clicking the “Lock” icon at the top right of your Facebook profile. You should probably set them to “Friends” or “Only Me” rather than “Public”:
Run A “Privacy Checkup” by clicking the “Lock” icon at the top right of your Facebook profile. You should probably set them to “Friends” or “Only Me” rather than “Public”: